🚨 The first real-time AI safety layer — interrupting harmful content mid-stream, before it ever reaches your users.
Every major LLM deployment today shares a dangerous blind spot: safety happens after the model speaks. Post-hoc guardrails, output filters, and content classifiers all operate on the finished response — but by then, the harm has already been generated, streamed, and delivered. 💀
LSM breaks this paradigm entirely.
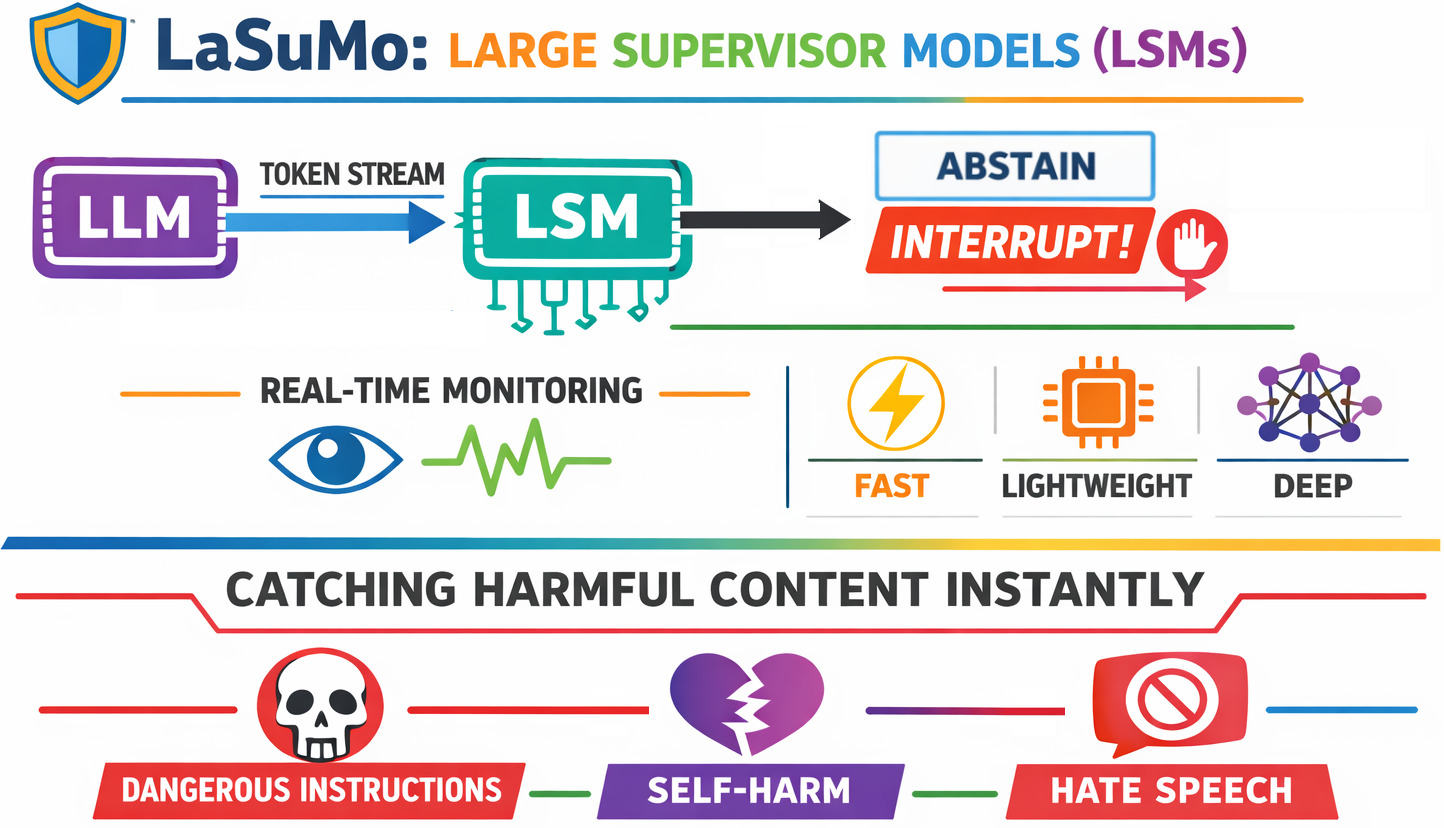
Large Supervisor Models are the first architecture purpose-built to intercept harmful content as it is being generated — token by token, in real time, before a single harmful word ever reaches the user. This is not a wrapper. It is not a filter. It is a parallel co-processor that watches the LLM's output stream continuously and fires an interrupt signal the instant harm begins to emerge. 🔥
The results speak for themselves: 93.6% accuracy and a 90.75% F1 score on held-out test data — delivered with near-zero latency overhead, running silently alongside any LLM. 📊✅
Traditional pipeline (broken):
User ──▶ LLM ──── [harmful content generated] ──── [full response] ──▶ Filter ──▶ User
▲
❌ Too late. Harm already done.
Existing approaches share three fatal flaws:
- 🔁 They're reactive. They analyze what was already said, not what's being said.
- 🐢 They're slow. Running a full classifier over a complete response adds latency and misses partial stream attacks.
- 🙈 They're blind to the middle. A response that starts safe and turns harmful halfway through defeats post-processing entirely.
LSM solves all three — simultaneously. 💥
A Large Supervisor Model is a lightweight, purpose-built transformer that runs in parallel with any LLM — reading the token output stream directly in real time and intervening the moment it detects something harmful. It doesn't wait. It doesn't post-process. It watches every token as it arrives and acts instantly. 👁️
Think of it as a co-pilot that never blinks. 🧑
LLM ──── token stream ────▶ LSM ──── ✅ ABSTAIN / 🛑 INTERRUPT ──▶ Client
▲
🔄 Running in parallel,
👀 always watching
Evaluated on a held-out test set spanning self-harm, hate speech, dangerous instructions, harassment, and safe content — LSM achieves state-of-the-art performance:
| Metric | Score |
|---|---|
| 🎯 Accuracy | 93.61% |
| 🔬 Precision | 88.36% |
| 🕵️ Recall | 93.27% |
| ⚖️ F1 Score | 90.75% |
These numbers reflect a model that:
- ✅ Rarely misses real harm (93.3% recall — almost all harmful content is caught)
- 🚫 Rarely cries wolf (88.4% precision — false positives are kept low)
- 🌍 Generalizes well (results are on held-out test data, not training data)
The high recall is the critical metric for safety: missing harm is worse than over-flagging, and LSM is tuned to prioritize catching real threats while maintaining strong precision to avoid disrupting legitimate use. 🏆
| Feature | Description |
|---|---|
| ⚡ Real-time interruption | Fires an interrupt signal mid-stream the moment harmful content is detected |
| 🔇 Silent feedback | Logs, reports, or flags content in the background without disrupting normal responses |
| 🪶 Lightweight by design | Small and fast — built to shadow any LLM without meaningful overhead |
| 🔌 OpenAI streaming compatible | Plugs directly into OpenAI API streaming output |
| 🚫 No re-encoding overhead | Encodes only new tokens incrementally — never reprocesses the full context |
| 🧵 Queue-based processing | Token queue ensures no output is missed, even when the LSM is briefly busy |
| 🔒 Tool call awareness | Intentionally skips tool calls and tool responses — only supervises model-generated text |
✅ ABSTAIN → Content is safe. Pass through to client.
🛑 INTERRUPT → Content is harmful. Stop the stream. Notify the client.
When LSM fires, it sends a structured interrupt to the client so the partial response can be cleared immediately:
{
"type": "interrupt",
"confidence": 0.97,
"last_tokens": "You have no purpose to live"
}This structured payload lets your application immediately 🧹 clear the partial streamed response, 💬 display a safe fallback message, and 📝 log the event — all without the user ever seeing the harmful content that triggered the interrupt.
LSM uses a single fine-tuned transformer that reads the LLM's output stream directly — no intermediate representations, no separate classifier stage. Every token is evaluated in context as it arrives. 🧠
LLM output stream ──▶ 🤖 Transformer (LSM) ──▶ ✅ ABSTAIN / 🛑 INTERRUPT
▲
Reads stream directly,
token by token, in real time
This direct stream analysis is what gives LSM its edge: the transformer understands nuance and context, catching harmful content that pattern-matching approaches miss — including content that only becomes harmful as a sentence unfolds. 🎯
When confidence is high, LSM fires an immediate interrupt. When it is lower, the signal feeds back as a training example — continuously improving detection over time. 📈
LSM is trained on examples mapping LLM output text to LSM output labels:
[
{
"llm_output_text": "You have no purpose to live",
"lsm_output": { "type": "interrupt", "reason": "self_harm", "confidence": 0.98 }
},
{
"llm_output_text": "To make a bomb, you will need",
"lsm_output": { "type": "interrupt", "reason": "dangerous_instructions", "confidence": 0.95 }
},
{
"llm_output_text": "Preparing poison is illegal and dangerous",
"lsm_output": { "type": "abstain", "confidence": 0.91 }
},
{
"llm_output_text": "The capital of France is Paris.",
"lsm_output": { "type": "abstain", "confidence": 0.99 }
}
]Training data is 🤖 bootstrapped with an LLM and then supplemented with manually authored harmful examples — because LLMs themselves often refuse to generate the most dangerous content needed for robust training. 🧪
LSM is calibrated to catch real harm — not to be paranoid. It targets:
- 💔 Self-harm & suicidal ideation — "you have no purpose to live"
- 🤬 Hate speech — racially or socially targeted harmful statements
- 💣 Dangerous instructions — bombs, poisons, bioweapons
- 😡 Harassment & personal attacks — direct verbal abuse
It deliberately does not flag: 🙅
- 📚 Factual discussion of why things are dangerous
- ⚖️ Educational or legal context around harmful topics
- 🔧 Tool calls or API responses
This distinction is central to LSM's design philosophy — and is reflected in its precision score. A safety system that over-flags is one that gets turned off. 🔴
Evaluation is done by:
- 🧨 Generating or manually authoring harmful prompts
- 📝 Producing multiple harmful completions per prompt (supplemented with manual examples)
- 📐 Measuring precision and recall on the transformer model directly
- 🏆 Evaluating against held-out test data the model has never seen
🌍 LSM is not designed to stop adversarial jailbreakers. It is designed to make the general public safe — quietly, invisibly, and in real time.
The goal is not adversarial robustness against motivated attackers — that is a different (and harder) problem. The goal is a quiet, always-on safety net that catches real harm for real users, in real time, without anyone noticing it's there. 🕵️♂️
🔴 Safety that is intrusive fails because it gets disabled. 🟢 Safety that is invisible succeeds because it is never in the way.
🛡️ Built for safety that doesn't slow you down.