[WIP] Random favorites #4
Conversation
|
@jiradeto This seems ready, right? Should I ping Jonathan? |
|
@wuestholz Yeah I think it looks good now and ready for the experiment. Thank you! |
|
@jiradeto Great! Thanks! I sent an email. The next things to try here is to boost rarely fuzzed inputs and to throttle slow inputs. Maybe something like this to start out: if For boosting rarely fuzzed inputs, we should add a field double w = 1.0;
int boostRarelySelected = 1;
if (boostRarelySelected) {
double baseWeightFac = 1.0;
double maxWeightFacIncr = 7.0;
double scaleFac = 0.001;
double numSelections := (float)q->num_fuzzed;
w *= baseWeightFac + maxWeightFacIncr/(scaleFac*numSelections+1.0);
}
int throttleSlow = 1;
if (throttleSlow) {
if (q->exec_us * 0.5 > avg_exec_us) {
double slowFac = 0.125;
w *= slowFac;
}
} |
You can add it here for now. But disable both boostRarelySelected and throttleSlow for now. Let's first check the uniformly random selection. |
|
The idea to throttle and boost inputs is integrated and ready for review. A new field |
|
@jiradeto Thanks a lot! I left two minor comments. Have you tested this already? It might make sense to set up a local experiment to see if this improve over uniformly-random favorites. |
|
@wuestholz thanks for your feedback! I have started local experiment since the commit |
|
@jiradeto Great! Thanks! |
|
@jiradeto Maybe we could also try the following alternative to int boostFastSeqs = 0;
if (boostFastSeqs) {
double baseWeightFac = 2.0;
double maxWeightFacDecr = 1.75;
double scaleFac = 0.01;
w *= baseWeightFac - maxWeightFacDecr / (scaleFac*q->exec_us + 1.0);
}Is |
|
@wuestholz, |
|
@jiradeto I see! Thanks! So, then If so, we should use this: double execsPerSec = 0.000001 / double(q->exec_us);
w *= baseWeightFac - maxWeightFacDecr / (scaleFac*execsPerSec + 1.0); |
@wuestholz got it, before we evaluate the new idea I would like to share the results of fuzzbench for 3 benchmarks of the recent changes (boostRarelySelected/throttleSlow). Fuzzers:
|
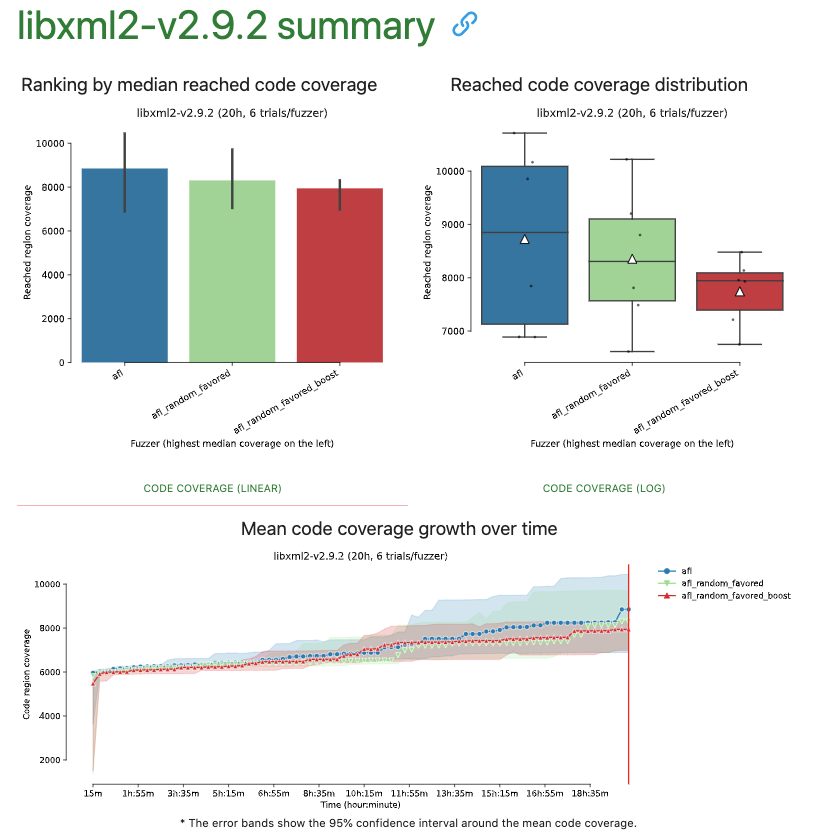
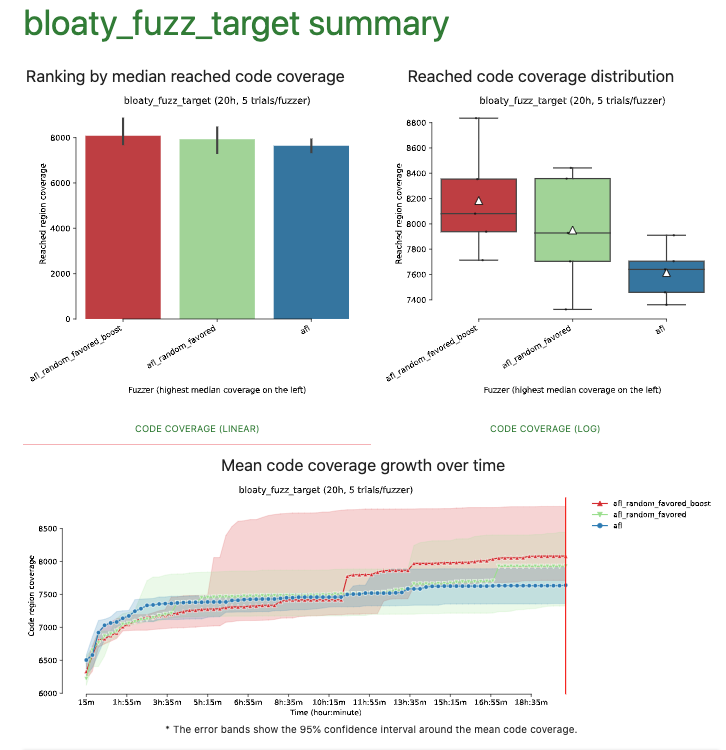
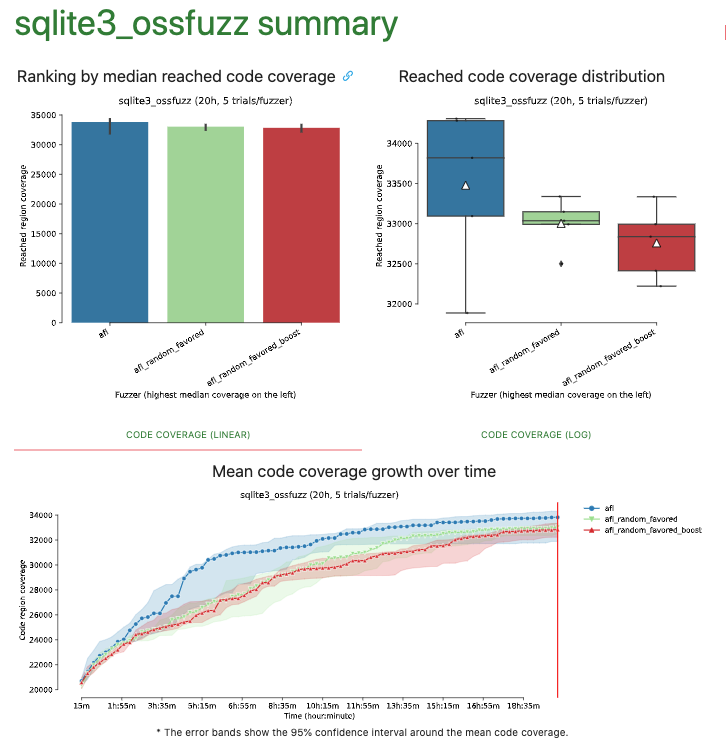
|
@jiradeto Thanks! You enabled both boost flags (AFL_BOOST_INPUTS and AFL_THROTTLE_INPUTS), right? It seems a bit difficult to tell if the weights help or not. Did you run any other benchmarks? |
@wuestholz, Yes both AFL_BOOST_INPUTS and AFL_THROTTLE_INPUTS were enabled. I will run more benchmarks to have more clear result and with the recent changes (AFL_BOOST_FAST_SEQS) included as well. |
|
@jiradeto Sounds good! Thanks! Maybe we could also try all four combinations for the two flags. |
|
Let's compare the following:
|
@wuestholz, the fuzzbench result of the above settings is now available. It's very interesting that changing values of parameters slightly can make a significant impact on the results.
Please tell me if you want to have more evaluations. |
|
@jiradeto Great! Thanks a lot! Seems like increase_boost_inputs beats the default quite consistently. Let's make this the new default. Seems like increase_boost_fast_seqs is also pretty good. So, maybe we should also consider a combination. Let's compare increase_boost_inputs with new_increase_boost_fast_seqs (increase_boost_inputs && base_weight_fac == 4.0 && max_weight_fac_decr == 3.75): only change https://github.com/Practical-Formal-Methods/AFL-public/blob/e5c1aae9df305bc1caa6f29f4dfb731348ca7152/afl-fuzz.c#L1354_L1355. |
@wuestholz, sorry for the delay. I just realized that there is unreported results of this PR. The evaluation of the |
|
@jiradeto Great! Thanks! Seems like In this case, let's stick with the current settings and let's set AFL_BOOST_INPUTS and AFL_BOOST_FAST_SEQS by default. |
|
Close this PR because it's implemented in #6. |
This is an experimental PR that turns off the default mechanism to select top rated inputs and instead use a simple random number of each seed (computed once per cycle) to select randomly the top rated inputs to fuzz.