Machine learning projects from Grokking Machine Learning by Luis Serrano
Welcome! This repository is a hands-on journey through the most important concepts in machine learning, with code, datasets, and visualizations for each chapter. Each notebook is designed for interactive learning and experimentation.
- Linear Regression: Predicting housing prices and visualizing regression lines
- Overfitting & Underfitting: How to test, regularize, and improve models
- Perceptron Algorithm: Sentiment analysis and binary classification
- Logistic Regression: Sentiment analysis with probabilistic models
- Naive Bayes: Text classification and probability-based predictions
- Decision Trees: App recommendations and interpretable models
- Neural Networks: Deep learning for house price prediction and image recognition
- Support Vector Machines (SVM): Building datasets, visualizing boundaries, and kernel tricks
- Ensemble Methods: AdaBoost, Random Forests, Gradient Boosting, and XGBoost for robust predictions
- End-to-End Example: Full machine learning pipeline on the Titanic dataset
- Unsupervised Learning: Image compression and clustering
- Expanded chapters on SVM, Ensemble Methods, and End-to-End ML pipelines
- More datasets for experimentation
- Advanced visualizations and interactive widgets
- Step-by-step explanations for each algorithm
- Real-world case studies and projects
- Tips for tuning and evaluating models
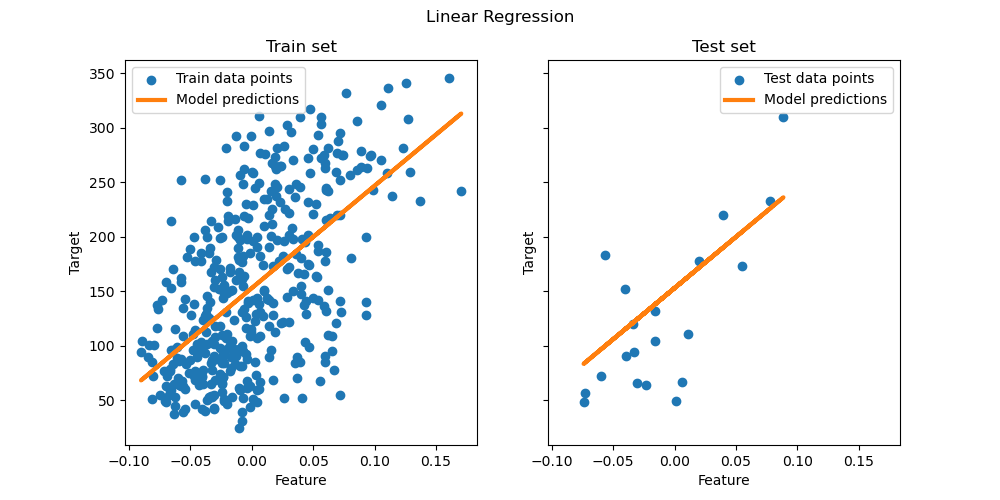
- Chapter 03: Linear Regression
- README
- Predicting housing prices with linear regression
- Chapter 04: Testing Overfitting & Underfitting
- README
- Regularization, train/test split, and model evaluation
- Chapter 05: Perceptron Algorithm
- Sentiment analysis using the perceptron algorithm
- Chapter 06: Logistic Regression
- Sentiment analysis with logistic regression
- Chapter 08: Naive Bayes
- Text classification using Naive Bayes
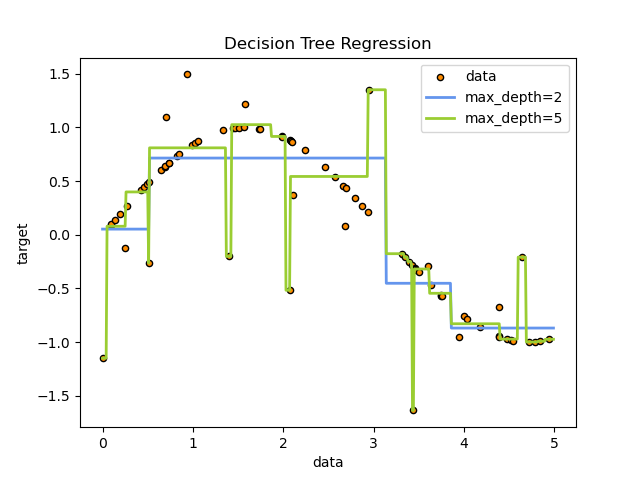
- Chapter 09: Decision Trees
- App recommendations and decision tree visualizations
- Chapter 10: Neural Networks
- House price prediction and image recognition with neural networks
- Chapter 11: Support Vector Machines (SVM)
- Building datasets, visualizing SVM boundaries, and kernel tricks
- Chapter 12: Ensemble Methods
- AdaBoost, Random Forests, Gradient Boosting, and XGBoost
- Chapter 13: End-to-End Example
- Full ML pipeline on the Titanic dataset
- Unsupervised Learning
- Image compression and clustering
Each chapter folder contains Jupyter notebooks and relevant datasets. For more details, see the README in each chapter (where available).
| Linear Regression | Decision Tree | Neural Network |
|---|---|---|
 |
 |
 |
- Clone the repository
- Open any chapter folder and launch the Jupyter notebook
- Follow the code and explanations to learn each concept
MIT License