-
pytorch处理图片时默认是NCHW格式,而pillow,opencv加载图像时则通常是HWC(height, width, channel), 这时候需要调整其维度顺序
- comfyui是NHWC的方式处理数据
- pytorch是一个tensor库, 自动微分库, 深度学习库
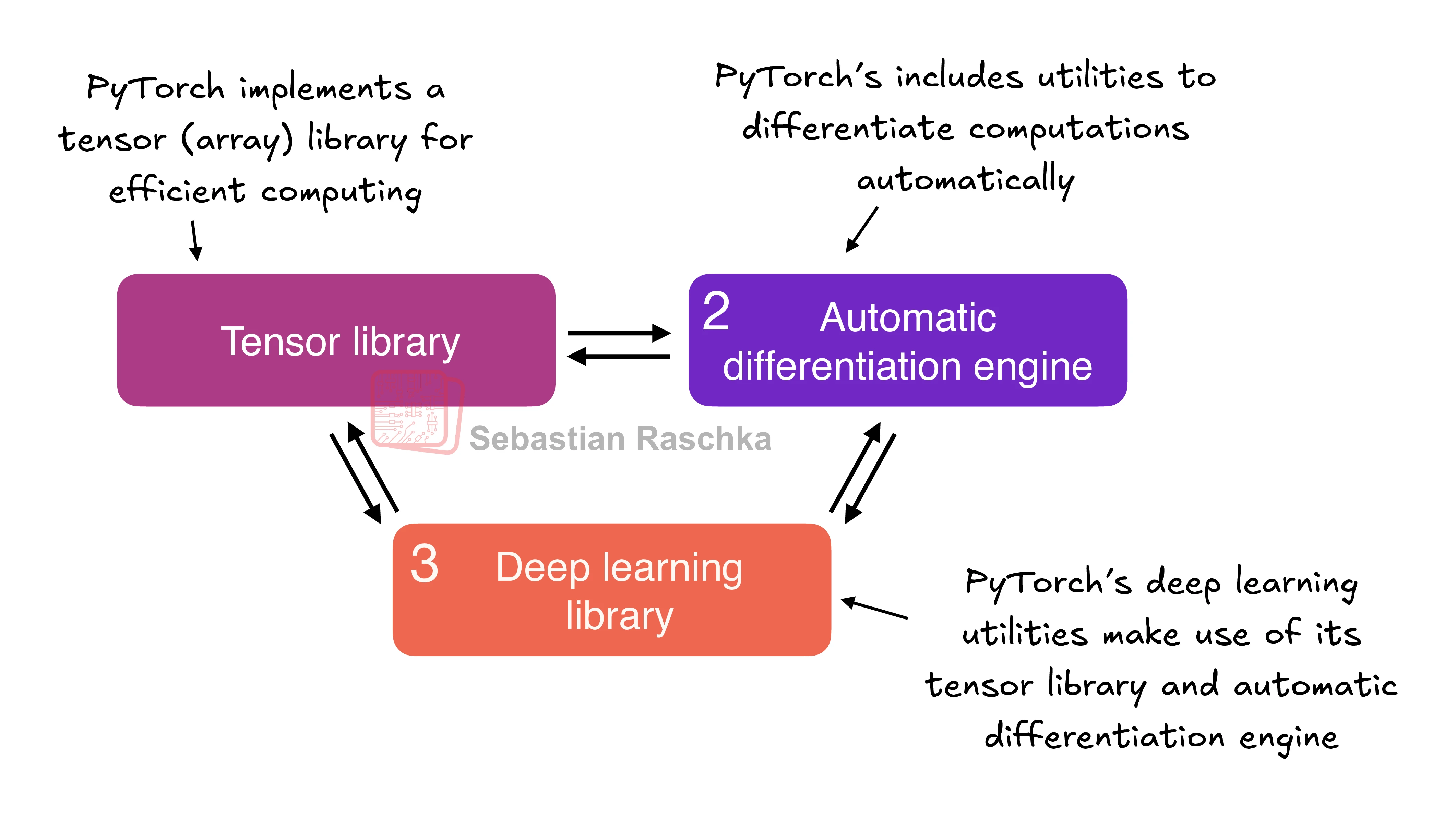
Firstly, PyTorch is a tensor library that extends the concept of array-oriented programming library NumPy with the additional feature of accelerated computation on GPUs, thus providing a seamless switch between CPUs and GPUs.
Secondly, PyTorch is an automatic differentiation engine, also known as autograd, which enables the automatic computation of gradients for tensor operations, simplifying backpropagation and model optimization.
Finally, PyTorch is a deep learning library, meaning that it offers modular, flexible, and efficient building blocks (including pre-trained models, loss functions, and optimizers) for designing and training a wide range of deep learning models, catering to both researchers and developers.
非常好的问题 👍
理解 PyTorch 的“核心对象与概念”是掌握深度学习底层逻辑的关键。下面我给你一个 系统性速查总结,涵盖核心类、模块层次与概念关系图。
| 层级 | 核心对象 / 模块 | 功能说明 |
|---|---|---|
| 底层 (Tensor & Autograd) | torch.Tensor, torch.autograd | 张量运算与自动求导 |
| 中层 (nn & optim) | torch.nn, torch.optim | 网络结构、层、损失函数、优化器 |
| 高层 (Data & utils) | torch.utils.data, torchvision, lightning | 数据加载、训练流程、可视化等 |
| 分类 | 核心类 / 函数 | 作用 |
|---|---|---|
| 张量 (Tensor) | torch.Tensor | 数据的基本载体(带梯度的多维数组) |
| torch.from_numpy(), torch.tensor() | 创建张量 | |
| Tensor.to(), Tensor.cuda() | 设备转换 | |
| 自动求导 (Autograd) | torch.autograd.Function | 自定义梯度运算 |
| Tensor.requires_grad, Tensor.backward() | 开启梯度、反向传播 | |
| torch.no_grad() | 关闭梯度计算(推理阶段) | |
| 神经网络模块 (nn) | torch.nn.Module | 所有网络、层、模型的基类 |
| nn.Linear, nn.Conv2d, nn.ReLU, nn.BatchNorm2d, … | 常见层 | |
| nn.Sequential, nn.ModuleList, nn.ModuleDict | 模块容器 | |
| nn.functional | 无状态函数式接口 | |
| 损失函数 (loss) | nn.CrossEntropyLoss, nn.MSELoss, nn.BCELoss, … | 计算预测与目标差异 |
| 优化器 (optim) | torch.optim.Optimizer | 优化器基类 |
| SGD, Adam, RMSprop, … | 各类梯度更新算法 | |
| scheduler | 学习率调度器(如 StepLR, CosineAnnealingLR) | |
| 数据处理 (data) | torch.utils.data.Dataset | 定义数据集读取逻辑 |
| torch.utils.data.DataLoader | 批量加载、并行读取 | |
| torchvision.transforms | 图像数据预处理 | |
| 设备与计算 | torch.device, torch.cuda, torch.backends.mps | 指定计算设备(CPU/GPU/MPS) |
| 保存与加载 | torch.save, torch.load, state_dict() | 模型与参数持久化 |
| 并行与分布式 | torch.nn.DataParallel, torch.distributed | 多 GPU / 多节点训练 |
| 随机性控制 | torch.manual_seed() | 复现性控制 |
-
PyTorch 的基本数据结构。
-
是带有自动求导能力的多维数组。
-
具有:
- 值(data)
- 梯度(grad)
- 计算图节点信息(grad_fn)
import torch
x = torch.randn(3, 3, requires_grad=True)
y = x * 2
z = y.mean()
z.backward()
print(x.grad)
- 动态图机制:计算图在前向传播时动态构建。
- 每个 Tensor 都有 grad_fn 属性,记录它的生成操作。
- backward() 会沿着计算图反向传播,自动求梯度。
PyTorch 使用反向传播 + 链式法则实现梯度传播。
-
所有模型(层)都继承自 nn.Module。
-
核心方法:
- init():定义子层与结构;
- forward():定义前向传播;
- .parameters():返回所有可训练参数;
- .state_dict():返回模型参数字典;
- .to(device):模型转设备。
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 256)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.relu(self.fc1(x))
return self.fc2(x)
- 根据梯度更新模型参数。
- 典型流程:
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 参数更新
- Dataset:定义数据读取逻辑;
- DataLoader:提供批量读取、打乱、并行加载。
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __getitem__(self, idx): ...
def __len__(self): ...
loader = DataLoader(MyDataset(), batch_size=32, shuffle=True)
- 控制计算在 CPU / GPU 上进行:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
- 每个 nn.Module 和 Optimizer 都有 state_dict()。
- 用于保存与加载权重:
torch.save(model.state_dict(), "model.pt")
model.load_state_dict(torch.load("model.pt"))
数据集 (Dataset) → DataLoader (batch)
↓
模型前向传播 (nn.Module)
↓
损失计算 (Loss)
↓
反向传播 (autograd)
↓
参数更新 (optimizer.step)
torch
├── Tensor # 基础数据结构
│ ├── data, grad, requires_grad
│ └── backward()
│
├── autograd # 自动求导系统
│ └── grad_fn, no_grad()
│
├── nn
│ ├── Module # 模型基类
│ ├── Layer # Linear, Conv2d, BatchNorm...
│ ├── Functional # 函数式接口
│ ├── Loss # CrossEntropyLoss, MSELoss...
│ └── Sequential # 模型容器
│
├── optim
│ ├── Optimizer # SGD, Adam...
│ └── lr_scheduler
│
├── utils.data
│ ├── Dataset
│ └── DataLoader
│
└── device / save / load / distributed
| 模块 | 说明 |
|---|---|
| torchvision | 图像任务工具集(模型、数据集、预处理) |
| torchaudio | 音频处理 |
| torchtext | 文本任务数据管线 |
| torchmetrics | 统一指标计算 |
| pytorch-lightning | 高层训练框架封装 |
| torch.compile(2.0+) | 图模式编译加速 |
是否希望我帮你画一张 PyTorch 核心概念关系图(Tensor→Module→Autograd→Optimizer→DataLoader) 的结构图?
可以直观看清这些类之间的依赖和调用顺序。
张量(Tensor)操作:创建、索引、切片、变形、广播等。
自动微分(Autograd):requires_grad、backward()、grad。
神经网络模块(torch.nn):Linear、Conv2d、ReLU 等。
优化器(torch.optim):SGD、Adam 等。
损失函数(torch.nn.functional):MSE、CrossEntropyLoss 等。
The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, attention, matmul, pooling, and normalization. NVIDIA CUDA®深度神经网络库(cuDNN)是一个用于深度神经网络的 GPU 加速库。cuDNN 提供了针对标准例程(如正向和反向卷积、注意力、矩阵乘法、池化和归一化)的高度优化的实现。
- torch.nn
- torch.optim
- torch.autograd
- 构建快(building blocks)
- Tensor
- Autograd Module
- Neural Network Module
- Optimizers
- Data Loading and Processing
- UDA Support for GPU Computing:
# 创建模型, 也是一个神经网络节点
torch.nn.Module
# 利用多个GPU
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两-
DDP
-
pytorch Lightning
-
数据处理
- 准备
- 预处理
-
推理优化技术
- 量化
- 剪枝
- 知识蒸馏
- 数据蒸馏
-
模型定制化
-
训练
- 分布式训练
- 大规模并行计算
- 优化算法
- 学习率调整
- AdamW
-
计算优化
- 算子融合
-
训练优化
-
显存优化
-
加速
- ONNX
- TensorRT
- 量化 (Quantization): 降低模型精度以换取更快的推理速度。
数据工程师(Data Engineer)
- 负责数据采集、数据清洗、数据标注与数据管道建设。
- 需求:熟悉 SQL/NoSQL、ETL 工具及大数据处理技术。
机器学习工程师(Machine Learning Engineer)
- 负责预训练、微调及模型部署;优化模型性能与资源占用。
- 需求:精通深度学习框架(如 PyTorch、TensorFlow)、分布式训练、超参数调优等技术。
深度学习研究员(Deep Learning Researcher/Scientist)
- 负责新模型架构探索、优化算法研究以及前沿技术应用。
- 需求:扎实的理论基础与创新能力,熟悉最新的研究进展与论文。
MLOps 工程师(MLOps Engineer)
- 负责模型从开发到生产环境的自动化部署、监控与维护。
- 需求:熟悉容器化(Docker/Kubernetes)、CI/CD 工具、监控与日志分析系统。
推理优化工程师(Inference Optimization Engineer)
- 专注于模型在生产环境下的推理速度、延迟和资源消耗优化。
- 需求:了解模型量化、剪枝、知识蒸馏等优化方法,熟悉 GPU 加速技术。
系统架构师(System Architect)
- 设计并整合数据、模型训练与推理的全链路系统架构,确保系统稳定性与可扩展性。
- 需求:深刻理解分布式系统、云服务和大规模并行计算。
数据科学家(Data Scientist)
- 分析模型效果、设计评估指标,并从数据中挖掘改进方向。
- 需求:统计分析、数据可视化及相关建模工具的熟练应用。
AI 安全与伦理专家(AI Safety & Ethics Specialist)
- 监控模型的安全性、伦理合规性,确保模型输出符合社会规范。
- 需求:跨学科知识背景,理解法律、伦理及数据隐私相关要求。
产品经理(Product Manager)
- 协调技术团队与业务需求,定义模型功能与发展路线。
- 需求:良好的沟通协调能力,了解人工智能产品全生命周期管理。
- 蒸馏
- 微调(fine-tune)
- 微调开源模型
- Adaptor
- LoRA
- 优化
- 调优
- RAG
- 数据需要实时更新
- Agent
- 技术深度:
- 理论知识:统计学习、深度学习理论与算法;
- 实践经验:大规模分布式训练、模型调优及性能优化;
- 编程能力:优先使用 Python、熟悉框架(如 Hugging Face Transformers、PyTorch/TensorFlow)。
- 工具与平台:
- 分布式训练工具:如 Horovod、DeepSpeed、Megatron-LM;
- 数据库及数据处理:首选 PostgreSQL 与 SQLAlchemy(对于 Python);
- 容器化与部署工具:Docker、Kubernetes;
- 监控工具:Prometheus、Grafana 等。
- 跨团队协作:
- 与数据、产品、运维等多方紧密合作,保证项目从数据到部署的顺畅对接。
- 持续学习与创新:
- 跟踪前沿研究,结合最新技术不断优化模型架构和算法,提升模型性能与应用价值。
二维矩阵(batch, feature)
三维矩阵(batch/sample, sequence, feature/embeding)
- https://pytorch.org/tutorials/beginner/ddp_series_theory.html
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
- https://www.youtube.com/watch?v=-K3bZYHYHEA&ab_channel=PyTorch Part 1: Welcome to the Distributed Data Parallel (DDP) Tutorial Series
- https://www.youtube.com/watch?v=Cvdhwx-OBBo&t=177s&ab_channel=PyTorch
nccl(默认无需配置)
torchrun
# 使用torchrun 启动分布式训练
import torch.distributed as dist # 该模块已经预先实现了所有需要
# 对于使用者来说, 多个节点的训练就像是在单机训练一样