diff --git a/README.md b/README.md
index d16bdf3e..469db9d6 100644
--- a/README.md
+++ b/README.md
@@ -10,13 +10,14 @@
-[English](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/README.md) | [中文](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/chinese.md) | [日本語](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/japanese.md)
-| [한국어](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/korean.md)
-| [Русский](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/russian.md) | [Türkçe](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/turkish.md)
+[English](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/README.md) | [中文](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/chinese.md) | [日本語](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/japanese.md)
+| [한국어](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/korean.md)
+| [Русский](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/russian.md) | [Türkçe](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/turkish.md)
| [Deutsch](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=de)
| [Español](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=es)
| [français](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=fr)
-| [Português](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/portuguese.md)
+| [Português](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/portuguese.md)
+| [Italiano](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/italian.md)
[](https://pepy.tech/projects/scrapegraphai)
@@ -24,7 +25,7 @@
[](https://discord.gg/gkxQDAjfeX)
- +
+
[ScrapeGraphAI](https://scrapegraphai.com) is a *web scraping* python library that uses LLM and direct graph logic to create scraping pipelines for websites and local documents (XML, HTML, JSON, Markdown, etc.).
@@ -163,7 +164,7 @@ Check out also the Docusaurus [here](https://docs-oss.scrapegraphai.com/).
Feel free to contribute and join our Discord server to discuss with us improvements and give us suggestions!
-Please see the [contributing guidelines](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/CONTRIBUTING.md).
+Please see the [contributing guidelines](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/CONTRIBUTING.md).
[](https://discord.gg/uJN7TYcpNa)
[](https://www.linkedin.com/company/scrapegraphai/)
@@ -187,7 +188,7 @@ The Official API Documentation can be found [here](https://docs.scrapegraphai.co
We collect anonymous usage metrics to enhance our package's quality and user experience. The data helps us prioritize improvements and ensure compatibility. If you wish to opt-out, set the environment variable SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. For more information, please refer to the documentation [here](https://scrapegraph-ai.readthedocs.io/en/latest/scrapers/telemetry.html).
## ❤️ Contributors
-[](https://github.com/VinciGit00/Scrapegraph-ai/graphs/contributors)
+[](https://github.com/ScrapeGraphAI/Scrapegraph-ai/graphs/contributors)
## 🎓 Citations
If you have used our library for research purposes please quote us with the following reference:
@@ -196,7 +197,7 @@ If you have used our library for research purposes please quote us with the foll
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
- url = {https://github.com/VinciGit00/Scrapegraph-ai},
+ url = {https://github.com/ScrapeGraphAI/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
```
@@ -209,7 +210,7 @@ If you have used our library for research purposes please quote us with the foll
## 📜 License
-ScrapeGraphAI is licensed under the MIT License. See the [LICENSE](https://github.com/VinciGit00/Scrapegraph-ai/blob/main/LICENSE) file for more information.
+ScrapeGraphAI is licensed under the MIT License. See the [LICENSE](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/LICENSE) file for more information.
## Acknowledgements
diff --git a/docs/italian.md b/docs/italian.md
new file mode 100644
index 00000000..eb0644c1
--- /dev/null
+++ b/docs/italian.md
@@ -0,0 +1,241 @@
+## 🚀 **Cerchi un modo ancora più veloce e semplice per fare scraping su larga scala (con sole 5 righe di codice)?** Scopri la nostra versione potenziata su [**ScrapeGraphAI.com**](https://scrapegraphai.com/?utm_source=github&utm_medium=readme&utm_campaign=oss_cta&utm_content=top_banner)! 🚀
+
+---
+
+# 🕷️ ScrapeGraphAI: You Only Scrape Once
+
+
+
+  +
+
+
+
+
+[English](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/README.md) | [中文](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/chinese.md) | [日本語](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/japanese.md)
+| [한국어](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/korean.md)
+| [Русский](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/russian.md) | [Türkçe](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/turkish.md)
+| [Deutsch](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=de)
+| [Español](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=es)
+| [français](https://www.readme-i18n.com/ScrapeGraphAI/Scrapegraph-ai?lang=fr)
+| [Português](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/portuguese.md)
+| [Italiano](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/docs/italian.md)
+
+[](https://pepy.tech/projects/scrapegraphai)
+[](https://github.com/pylint-dev/pylint)
+[](https://github.com/ScrapeGraphAI/Scrapegraph-ai/actions/workflows/code-quality.yml)
+[](https://github.com/ScrapeGraphAI/Scrapegraph-ai/actions/workflows/codeql.yml)
+[](https://opensource.org/licenses/MIT)
+[](https://discord.gg/gkxQDAjfeX)
+
+[](https://scrapegraphai.com/?utm_source=github&utm_medium=readme&utm_campaign=api_banner&utm_content=api_banner_image)
+
+
+
+
+
+[ScrapeGraphAI](https://scrapegraphai.com) è una libreria Python per il *web scraping* che utilizza LLM e logica basata sui grafi per creare pipeline di scraping per siti web e documenti locali (XML, HTML, JSON, Markdown, ecc.).
+
+Indica semplicemente quali informazioni vuoi estrarre e la libreria lo farà per te!
+
+
+ 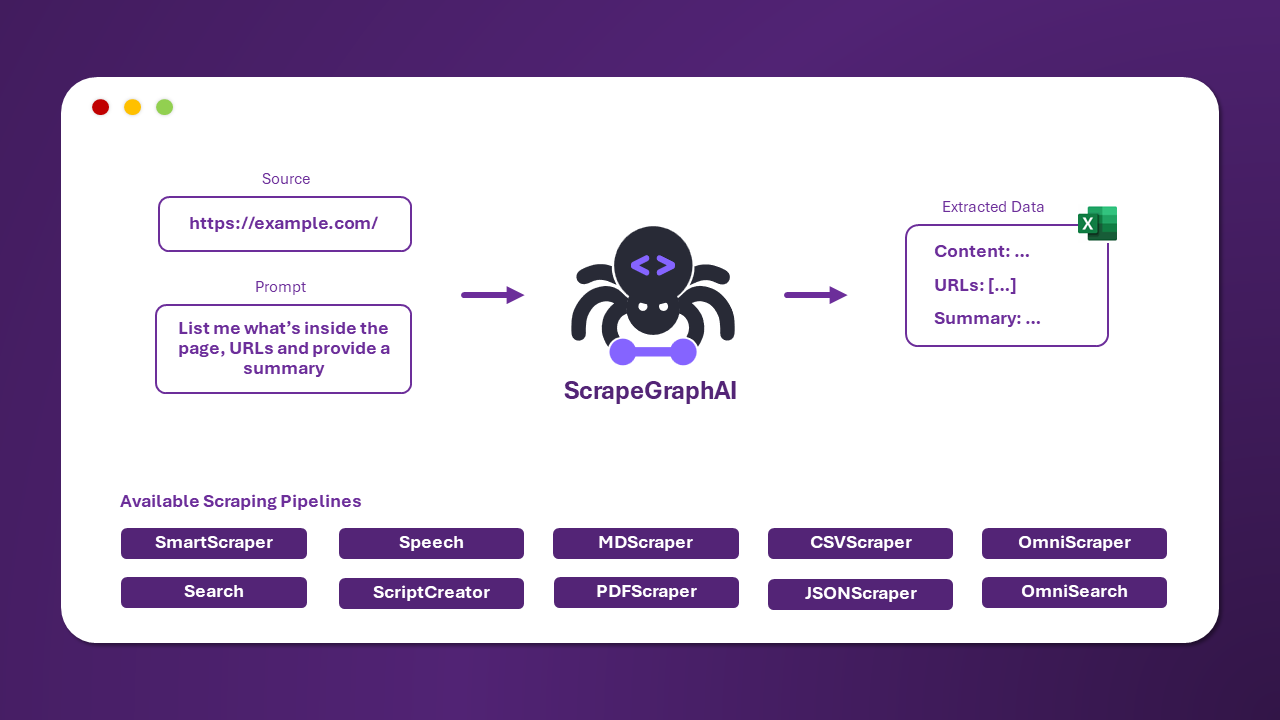 +
+
+
+## 🚀 Integrazioni
+
+ScrapeGraphAI offre integrazioni con i framework e gli strumenti più diffusi per potenziare le tue capacità di scraping. Che tu stia sviluppando in Python o Node.js, usando framework LLM o piattaforme no-code, offriamo un'ampia gamma di opzioni di integrazione.
+
+Puoi trovare ulteriori informazioni al seguente [link](https://scrapegraphai.com)
+
+**Integrazioni**:
+- **API**: [Documentazione](https://docs.scrapegraphai.com/introduction)
+- **SDK**: [Python](https://docs.scrapegraphai.com/sdks/python), [Node](https://docs.scrapegraphai.com/sdks/javascript)
+- **Framework LLM**: [Langchain](https://docs.scrapegraphai.com/integrations/langchain), [Llama Index](https://docs.scrapegraphai.com/integrations/llamaindex), [Crew.ai](https://docs.scrapegraphai.com/integrations/crewai), [Agno](https://docs.scrapegraphai.com/integrations/agno), [CamelAI](https://github.com/camel-ai/camel)
+- **Framework Low-code**: [Pipedream](https://pipedream.com/apps/scrapegraphai), [Bubble](https://bubble.io/plugin/scrapegraphai-1745408893195x213542371433906180), [Zapier](https://zapier.com/apps/scrapegraphai/integrations), [n8n](http://localhost:5001/dashboard), [Dify](https://dify.ai), [Toolhouse](https://app.toolhouse.ai/mcp-servers/scrapegraph_smartscraper)
+- **Server MCP**: [Link](https://smithery.ai/server/@ScrapeGraphAI/scrapegraph-mcp)
+
+## 🚀 Installazione rapida
+
+La pagina di riferimento per scrapegraph-ai è disponibile sulla pagina ufficiale di PyPI: [pypi](https://pypi.org/project/scrapegraphai/).
+
+```bash
+pip install scrapegraphai
+
+# IMPORTANTE (per il recupero del contenuto dei siti web)
+playwright install
+```
+
+**Nota**: si consiglia di installare la libreria in un ambiente virtuale per evitare conflitti con altre librerie 🐱
+
+## 💻 Utilizzo
+
+Esistono diverse pipeline di scraping predefinite che possono essere utilizzate per estrarre informazioni da un sito web (o da un file locale).
+
+La più comune è `SmartScraperGraph`, che estrae informazioni da una singola pagina dato un prompt dell'utente e un URL sorgente.
+
+```python
+from scrapegraphai.graphs import SmartScraperGraph
+
+# Definisci la configurazione per la pipeline di scraping
+graph_config = {
+ "llm": {
+ "model": "ollama/llama3.2",
+ "model_tokens": 8192,
+ "format": "json",
+ },
+ "verbose": True,
+ "headless": False,
+}
+
+# Crea l'istanza di SmartScraperGraph
+smart_scraper_graph = SmartScraperGraph(
+ prompt="Estrai informazioni utili dalla pagina web, inclusa una descrizione di cosa fa l'azienda, i fondatori e i link ai social media",
+ source="https://scrapegraphai.com/",
+ config=graph_config
+)
+
+# Esegui la pipeline
+result = smart_scraper_graph.run()
+
+import json
+print(json.dumps(result, indent=4))
+```
+
+> [!NOTE]
+> Per OpenAI e altri modelli è sufficiente modificare la configurazione llm!
+> ```python
+> graph_config = {
+> "llm": {
+> "api_key": "LA_TUA_OPENAI_API_KEY",
+> "model": "openai/gpt-4o-mini",
+> },
+> "verbose": True,
+> "headless": False,
+> }
+> ```
+
+L'output sarà un dizionario simile al seguente:
+
+```python
+{
+ "description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
+ "founders": [
+ {
+ "name": "",
+ "role": "Founder & Technical Lead",
+ "linkedin": "https://www.linkedin.com/in/perinim/"
+ },
+ {
+ "name": "Marco Vinciguerra",
+ "role": "Founder & Software Engineer",
+ "linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
+ },
+ {
+ "name": "Lorenzo Padoan",
+ "role": "Founder & Product Engineer",
+ "linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
+ }
+ ],
+ "social_media_links": {
+ "linkedin": "https://www.linkedin.com/company/101881123",
+ "twitter": "https://x.com/scrapegraphai",
+ "github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
+ }
+}
+```
+
+Esistono altre pipeline che possono essere utilizzate per estrarre informazioni da più pagine, generare script Python o persino generare file audio.
+
+| Nome Pipeline | Descrizione |
+|-------------------------|------------------------------------------------------------------------------------------------------------------|
+| SmartScraperGraph | Scraper di singole pagine che richiede solo un prompt utente e una sorgente. |
+| SearchGraph | Scraper multi-pagina che estrae informazioni dai primi n risultati di un motore di ricerca. |
+| SpeechGraph | Scraper di singole pagine che estrae informazioni da un sito web e genera un file audio. |
+| ScriptCreatorGraph | Scraper di singole pagine che estrae informazioni da un sito web e genera uno script Python. |
+| SmartScraperMultiGraph | Scraper multi-pagina che estrae informazioni da più pagine dato un singolo prompt e una lista di sorgenti. |
+| ScriptCreatorMultiGraph | Scraper multi-pagina che genera uno script Python per estrarre informazioni da più pagine e sorgenti. |
+
+Per ciascuno di questi grafi esiste una versione multi, che consente di effettuare chiamate all'LLM in parallelo.
+
+È possibile utilizzare diversi LLM tramite API, come **OpenAI**, **Groq**, **Azure**, **Gemini**, **MiniMax** e altri, oppure modelli locali tramite **Ollama**.
+
+Ricordati di avere [Ollama](https://ollama.com/) installato e di scaricare i modelli con il comando **ollama pull**, se desideri utilizzare modelli locali.
+
+## 📖 Documentazione
+
+[](https://colab.research.google.com/drive/1sEZBonBMGP44CtO6GQTwAlL0BGJXjtfd?usp=sharing)
+
+La documentazione di ScrapeGraphAI è disponibile [qui](https://scrapegraph-ai.readthedocs.io/en/latest/).
+Consulta anche il Docusaurus [qui](https://docs-oss.scrapegraphai.com/).
+
+## 🤝 Vuoi contribuire?
+
+Sentiti libero di contribuire e unisciti al nostro server Discord per discutere con noi su cosa migliorare e darci suggerimenti!
+
+Consulta le [linee guida per i contributi](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/CONTRIBUTING.md).
+
+[](https://discord.gg/uJN7TYcpNa)
+[](https://www.linkedin.com/company/scrapegraphai/)
+[](https://twitter.com/scrapegraphai)
+
+## 🔗 API e SDK di ScrapeGraph
+
+Se stai cercando una soluzione rapida per integrare ScrapeGraph nel tuo sistema, scopri la nostra potente API [qui!](https://dashboard.scrapegraphai.com/login)
+
+[](https://dashboard.scrapegraphai.com/login)
+
+Offriamo gli SDK sia in Python che in Node.js, per una facile integrazione nei tuoi progetti. Scoprili di seguito:
+
+| SDK | Linguaggio | Link GitHub |
+|------------|------------|-----------------------------------------------------------------------------|
+| Python SDK | Python | [scrapegraph-py](https://github.com/ScrapeGraphAI/scrapegraph-sdk/tree/main/scrapegraph-py) |
+| Node.js SDK | Node.js | [scrapegraph-js](https://github.com/ScrapeGraphAI/scrapegraph-sdk/tree/main/scrapegraph-js) |
+
+La documentazione ufficiale dell'API è disponibile [qui](https://docs.scrapegraphai.com/).
+
+## 🔥 Benchmark
+
+Secondo il benchmark di Firecrawl [Firecrawl benchmark](https://github.com/firecrawl/scrape-evals/pull/3), ScrapeGraph è il miglior fetcher sul mercato!
+
+
+
+## 📈 Telemetria
+
+Raccogliamo metriche di utilizzo anonimizzate per migliorare la qualità e la user experience del nostro pacchetto. I dati ci aiutano a stabilire le priorità e a garantire la compatibilità. Se desideri disattivare la telemetria, imposta la variabile d'ambiente `SCRAPEGRAPHAI_TELEMETRY_ENABLED=false`. Per ulteriori informazioni, consulta la documentazione [qui](https://scrapegraph-ai.readthedocs.io/en/latest/scrapers/telemetry.html).
+
+## ❤️ Collaboratori
+
+[](https://github.com/ScrapeGraphAI/Scrapegraph-ai/graphs/contributors)
+
+## 🎓 Citazioni
+
+Se hai utilizzato la nostra libreria per scopi di ricerca, citaci con il seguente riferimento:
+
+```text
+ @misc{scrapegraph-ai,
+ author = {Lorenzo Padoan, Marco Vinciguerra},
+ title = {Scrapegraph-ai},
+ year = {2024},
+ url = {https://github.com/ScrapeGraphAI/Scrapegraph-ai},
+ note = {A Python library for scraping leveraging large language models}
+ }
+```
+
+## Autori
+
+| | Contatti |
+|--------------------|----------------------|
+| Marco Vinciguerra | [](https://www.linkedin.com/in/marco-vinciguerra-7ba365242/) |
+| Lorenzo Padoan | [](https://www.linkedin.com/in/lorenzo-padoan-4521a2154/) |
+
+## 📜 Licenza
+
+ScrapeGraphAI è rilasciato sotto la Licenza MIT. Consulta il file [LICENSE](https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/LICENSE) per ulteriori informazioni.
+
+## Ringraziamenti
+
+- Ringraziamo tutti i collaboratori del progetto e la comunità open-source per il loro supporto.
+- ScrapeGraphAI è destinato esclusivamente a scopi di esplorazione dei dati e ricerca. Non siamo responsabili per eventuali usi impropri della libreria.
+
+Fatto con il ❤️ da [ScrapeGraph AI](https://scrapegraphai.com)
+
+[Scarf tracking](https://static.scarf.sh/a.png?x-pxid=102d4b8c-cd6a-4b9e-9a16-d6d141b9212d)